数据信息 / Arrow Data
欢迎回到 DORA 教程!在事件流中,我们学习了节点和算子通过事件流接收信息,包括携带数据的 INPUT 事件。但是,这些数据在事件内部是什么样的? DORA 又是如何高效地传输这些数据的,尤其是对于图像或传感器读数等大数据项?
本章深入探讨 DORA 数据处理的核心: 数据信息 及其对 Apache Arrow 格式的使用。
对速度的需求:处理大数据
再次想象一下我们的对象检测数据流:相机节点生成图像,对象检测节点处理它们,绘图节点将它们可视化。
- 图像通常很大(例如,具有 3 个颜色通道的 640x480 像素超过 900 KB)。
- 传感器数据(例如来自
LiDAR传感器的点云)可以更大。
这些海量数据需要快速地从一个 Node 进程传输到另一个 Node 进程。如果 DORA 每次将图像从摄像头节点发送到物体检测节点,然后再发送到绘图节点时,都必须完整复制一份,这将浪费大量的时间和内存。这在毫秒必争的实时应用中尤其糟糕。
我们需要一种以最小的开销在进程之间共享或移动这些数据的方法。
数据信息和 Apache Arrow
在 DORA 中,当数据到达输入时,它是 INPUT 事件的一部分, DORA 实际的数据有效负载被包装在数据信息中。DORA 使用称为 Apache Arrow 的强大标准来表示大多数数据信息中的数据。
Apache Arrow 是一种高度优化、标准化的内存数据组织方式。Arrow 并非只是提供每个人都必须以不同方式解释的原始字节流,而是为数字列表、数组、表等常见数据类型提供了定义的结构。
为什么选择 Arrow?
- 标准化: 为跨不同编程语言和系统的数据提供通用语言。
- 性能: 它专为分析处理和数据传输而设计,特别是支持“零拷贝读取”。
- 零拷贝: 这是
DORA的关键部分。如果数据位于共享内存中,并且格式为Arrow,则多个进程可以从同一内存位置读取数据,而无需将数据复制到各自的地址空间中。
因此,当节点或算子接收到 INPUT 事件时,该事件的 value 部分通常是一个 Arrow 数组 (有时是一个包含多个 Arrow 数组的结构体)。Arrow 数组是 Arrow 术语,指一系列相同类型的值(例如整数列表、浮点数列表或表示图像的字节列表)。
在代码中使用 Arrow Data
当你在 Node 或 Operator 代码中收到 INPUT 事件时, event["value"] (Python 中)会返回数据。DORA 会封装这些数据,通常允许你以 Arrow 对象的形式访问它,或者轻松地将其转换为你编程语言中的常见数据结构(例如 Python 中的 NumPy 数组)。
下面是一个概念性的 Python 代码片段,展示了如何接收图像数据:
这表明数据以 dora API 提供的格式到达,该 API 基于 Arrow。然后,您可以使用 API 提供的方法(通常利用 Python 中的 pyarrow 库)来访问数据,或将数据转换为适合您处理逻辑的格式。
类似地,发送数据时,您需要将其格式化为 Arrow 数组或与 Arrow 兼容的结构,然后通过 node.send_output(...) 或 send_output(...) 将其发送给 Operator。dora API 可以帮助 DORA 进行这种格式化。
底层:共享内存和零拷贝
DORA 如何实现性能提升,尤其是“零拷贝”?
对于较大的数据有效载荷(超过一定的大小阈值,由核心代码中的 ZERO_COPY_THRESHOLD 定义,当前为 4KB), DORA 使用共享内存 。
以下是 节点A 向 节点B 发送大数据信息时的简化流程:
节点 A以Apache Arrow格式准备数据。节点 A告诉dora 运行时(通过控制通道)它想要在特定的输出上发送该数据。dora 运行时分配了一块共享内存。这块内存节点 A和节点 B进程都可以访问。节点 A将 Arrow 格式的数据写入此共享内存块。- 然后,
dora 运行时向节点 B发送一个 INPUT 事件。此事件不包含数据本身,而是包含数据所在的共享内存块的引用或标识符 ,以及Arrow结构信息(类型、大小、布局),DORA其称为ArrowTypeInfo,是消息Metadata的一部分。 节点 B收到INPUT事件,从Metadata中读取共享内存标识符和ArrowTypeInfo。节点 B使用其dora API访问数据。该API知道如何将共享内存块映射(使其可访问)到节点 B的进程中,并使用 Arrow 格式信息直接从那里读取数据。
这是一个简化的序列图:
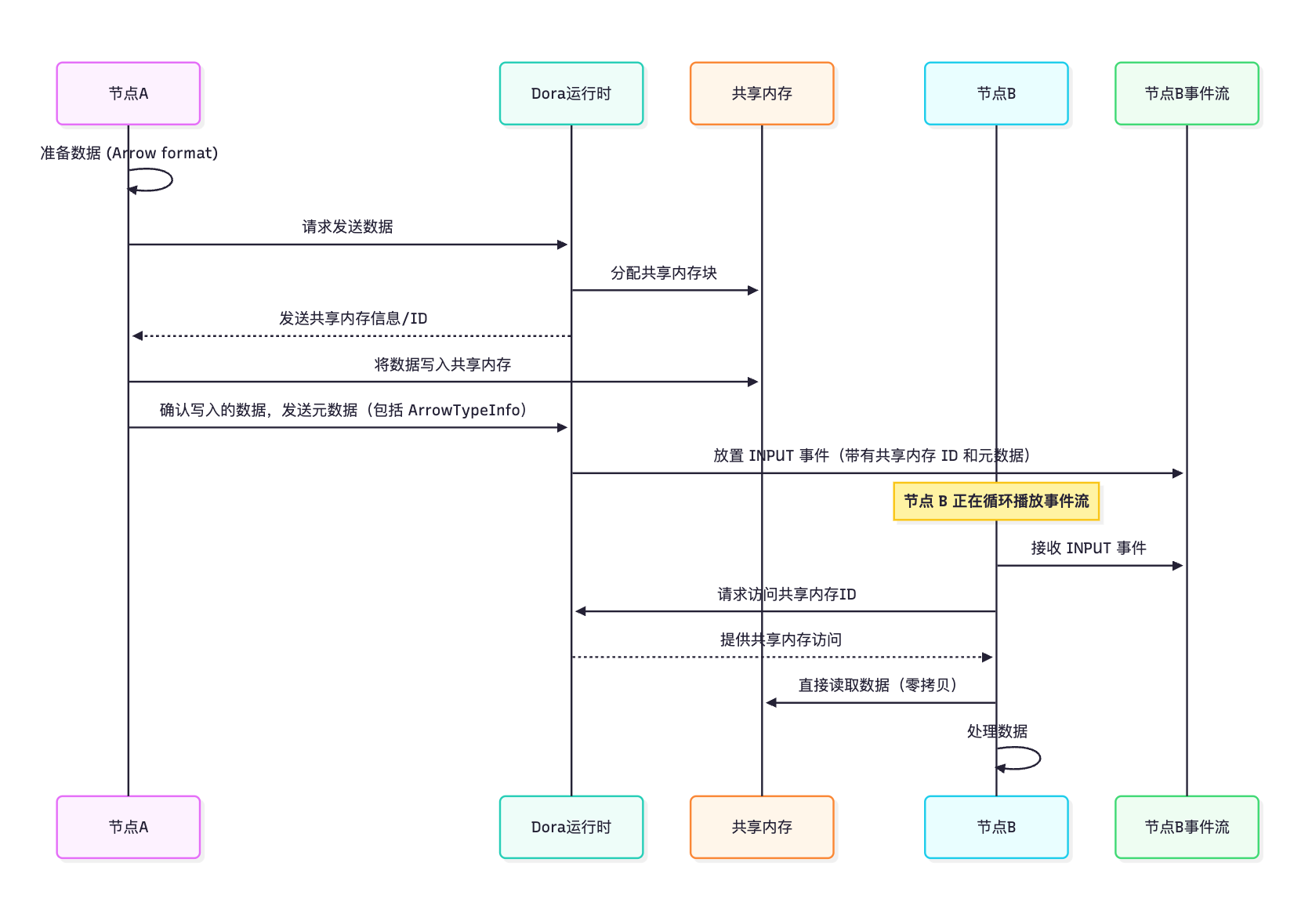
这种从共享内存直接读取(“零拷贝”)的方式使得 DORA 能够快速传输大量数据信息,因为数据本身不需要序列化、通过管道发送,也不需要由接收进程反序列化。
对于小数据有效载荷(低于 ZERO_COPY_THRESHOLD ),数据可能会直接在消息本身内发送(例如,通过通信管道复制),因为设置共享内存的开销可能大于复制小数据的成本。
管理共享内存:删除令牌
共享内存的一个关键挑战是知道何时可以安全地释放内存。如果发送节点过早释放内存,接收节点在尝试访问时可能会崩溃。 DORA 使用一种涉及丢弃令牌的机制来管理这个问题。
- 当
节点 A使用共享内存发送数据时,它会为该特定的共享内存块生成一个唯一的DropToken。 - dora 运行时指出,
节点 B(和任何其他订阅者)在处理完数据后需要得到通知。 节点 A跟踪它生成的DropToken。- 当
节点 B接收到数据并完成处理时(例如,当接收到的数据对象超出其代码范围时),节点 B中的dora API会向运行时发回信号,表明它已完成与该共享内存ID/Drop Token相对应的数据处理。 - dora 运行时会跟踪有多少节点接收了数据。当所有接收该特定数据块的节点都发出完成信号后,运行时会通过一个称为
Drop Stream的专用内部通道,向原始发送节点(节点 A)发送drop token完成”信号。 节点 A监听这些“drop token 完成”信号(由 dora Node API 内部处理)。当节点 A收到它之前发送的DropToken信号时,它就知道特定的共享内存块不再被任何下游节点需要,可以安全地释放或返回到缓存中以供重用。
此 Drop Token 机制确保仅在所有预期接收者完成访问后才回收共享内存。
您可以在 dora-node-api Rust 代码中看到对这些概念的引用:
libraries/message/src/common.rs中的DataMessage枚举具有SharedMemory变量,其中包括shared_memory_id、len和drop_token。DropToken结构也在libraries/message/src/common.rs中定义。ZERO_COPY_THRESHOLD在apis/rust/node/src/node/mod.rs中定义。apis/rust/node/src/node/mod.rs中的DoraNode结构包括sent_out_shared_memory(用于跟踪其发送的内存的令牌)和drop_stream(用于接收完成信号)等字段。apis/rust/node/src/node/mod.rs中的allocate_data_sample和handle_finished_drop_tokens等方法展示了分配共享内存和处理传入的删除令牌的内部逻辑。libraries/message/src/metadata.rs中的Metadata结构包含描述Arrow数据有效负载的结构的type_info(ArrowTypeInfo)。
总结
在本章中,我们了解到 DORA 中的数据是通过 INPUT 数据信息在节点和算子之间传递的。为了实现高性能,尤其是在处理大数据量时, DORA 主要使用 Apache Arrow 格式,并利用共享内存在进程间实现零拷贝数据传输。这意味着接收节点可以直接从发送节点写入的同一内存位置读取数据。Drop Token 机制确保此共享内存得到安全管理,并且仅在所有接收节点都处理完数据后才会释放。理解这些概念是理解 DORA 在实时数据管道中性能特征的关键。
现在您已经了解了数据如何流动和表示,让我们看看您将用来在 Node 或 Operator 代码中与 dora 运行时进行交互的工具: API Bingding 绑定 。
![]()

Dora中文社区 © 2025 doracc.com
苏ICP备14007268号-19 |  苏公网安备32050602013520号
苏公网安备32050602013520号
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可