节点
欢迎回到 DORA 的教程!在上一章:数据流中,我们了解到数据流是 DORA 系统的蓝图,它使用 YAML 文件定义了所有部分以及数据在它们之间流动的方式。
现在,让我们深入研究这些单独的部分 —— 节点 nodes。
应用程序中的工蜂
想象一下,你的数据流就像一张工厂车间蓝图,展示了不同的工作站以及传送带如何连接它们。节点是工厂里的各个工作站或工蜂。
节点是应用程序中一个独立的、自包含的工作单元。每个节点负责执行一项特定的任务。例如:
- 从传感器(如摄像头或麦克风)读取数据。
- 执行计算(如对象检测或过滤数据)。
- 控制硬件(如电机或灯)。
- 在屏幕上可视化数据。
其核心思想是每个节点都是独立的。它不需要知道前一个节点是如何工作的,只需要知道它产生了什么样的数据。同样,它也不需要知道谁会使用它的输出,只需要知道它自己产生了什么样的数据。
数据流蓝图中的节点
我们在上一章中看到了如何在数据流 YAML 中定义节点:
在此 YAML 中, nodes: 列表下的每个项目都定义一个节点:
id:这是数据流(camera、object_detection、plot)中节点的唯一名称。其他节点或DORA运行时可以通过此名称识别它。inputs:列出了此节点需要接收的数据流。例如,object_detection需要一个image输入。格式source_node_id/source_output_id指定哪个节点的输出流应该连接到此输入。这被称为“传入传送带”。outputs:列出了此节点生成或发送的数据流。例如,camera生成image输出。这被称为“输出传送带”。
YAML 中有关 Node 的其余信息(如 path 、 build 、 env )告诉 DORA 如何运行该特定 Node 的实际代码。
节点如何工作
虽然数据流 YAML 定义了哪些节点存在以及它们如何连接,但节点完成的实际工作是由其实现定义的。
Node 的实现是 DORA 启动该 Node 时运行的代码。此代码使用 dora Node API(可用于 Python、Rust、C/C++ 等语言)来执行以下操作:
- 接收输入 :监听到达其输入流的数据。
- 处理数据 :使用输入数据执行其特定任务。
- 发送输出 :产生结果并将其发送到其输出流。
以下是使用 Python API 概念性地展示的一个非常简单的 Node 代码中的核心逻辑(我们将在后面的章节中深入探讨 API):
这段代码片段展示了典型的流程:Node 代码初始化,然后进入循环等待事件(例如接收输入)。当输入到达时,它会执行其特定任务并发送结果。DORA 会根据您的 YAML 在后台处理所有通信设置。
节点作为独立进程
DORA 中节点的一个关键特性是它们通常作为单独的进程运行。分析一下当你使用 dora run your_dataflow.yml 的运行逻辑 :
DORA命令行界面(CLI)启动dora 运行时(如Dora Daemon和Dora Coordinator)。- 运行时读取您的
Dataflow YAML文件。 - 对于
YAML中定义的每个节点,运行时都会在您的计算机上启动一个新的独立进程。 - 然后,运行时使用
YAML中的inputs和outputs定义在这些单独的Node进程之间建立高效的通信通道(通常使用共享内存来提高速度)。
这种架构有几个优点:
- 隔离性: 如果一个节点崩溃(例如,由于其代码中的错误),通常不会影响其他节点。数据流可以继续运行或优雅地处理故障。
- 稳健性: 单独的流程可以更好地抵御某些类型的错误。
- 语言灵活性: 由于节点是通过标准机制进行通信的独立进程,因此您可以在同一数据流中使用不同的编程语言(
Python 节点、Rust 节点、C/C++ 节点等)实现不同的节点。 - 可扩展性: 在更高级的场景中,这种架构可以更轻松地将节点分布在不同的
CPU内核甚至不同的机器上。
下面是一个说明启动过程的简单序列图:
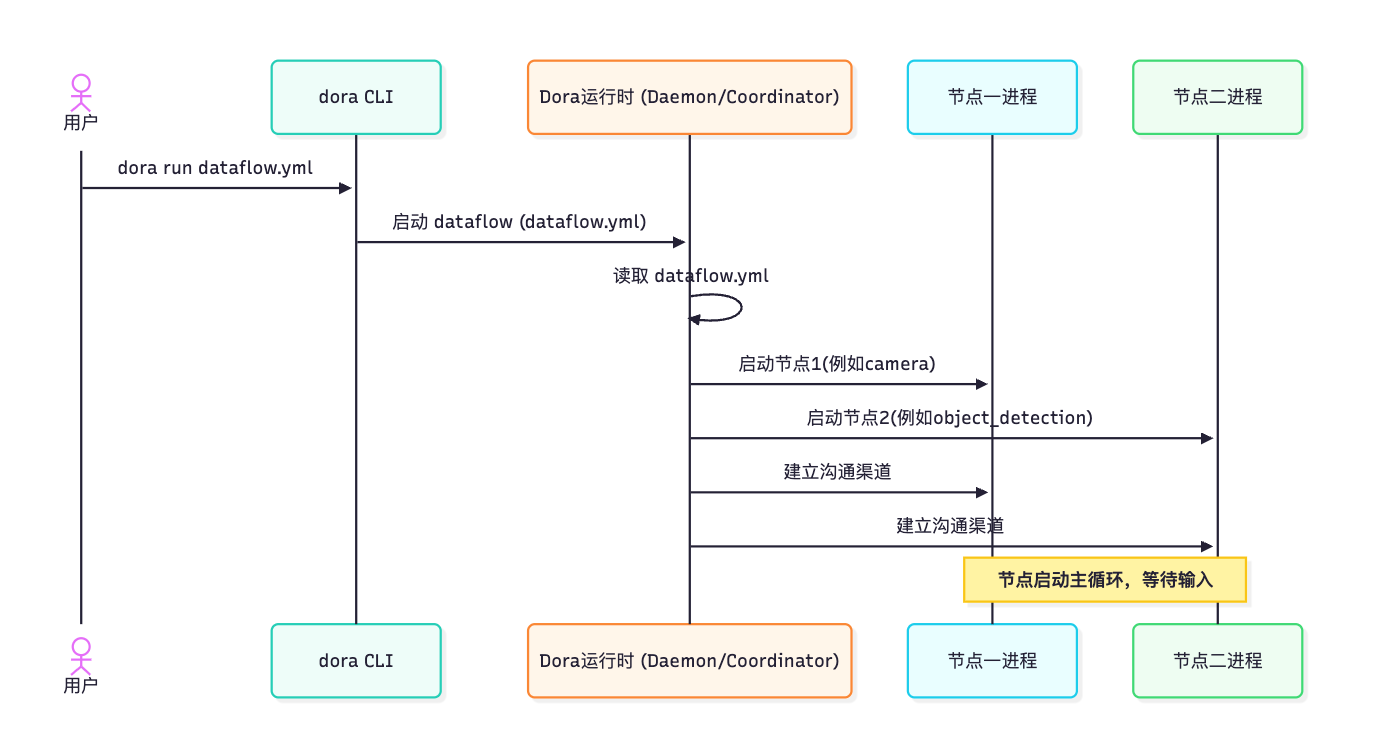
一旦运行时设置了通信通道,节点就可以通过这些通道直接相互发送数据,而无需运行时代理每条消息。
总结
在本章中,我们了解到节点是 DORA 数据流应用程序中独立的工作单元。它们在数据流 YAML 文件中定义,具有唯一的 ID、用于接收数据的特定输入以及用于生成数据的输出。每个节点都作为独立的进程运行,其内部逻辑(使用您选择的语言编写的 dora API)负责接收输入、执行任务和发送输出。Dora 运行时负责启动这些进程并根据 YAML 蓝图设置通信管道。
现在我们了解了各个处理单元(节点),让我们看一下在节点内部构建逻辑的常用方法,特别是在处理许多输入和输出时: Operator 算子 的概念。
![]()

Dora中文社区 © 2025 doracc.com
苏ICP备14007268号-19 |  苏公网安备32050602013520号
苏公网安备32050602013520号
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可